Spark
数据端配置
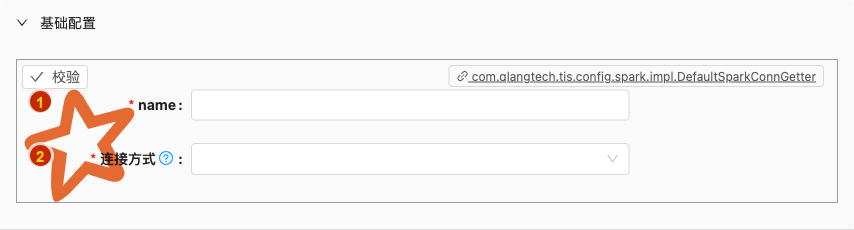
- 配置项说明:
name
- 类型: 单行文本
- 必须: 是
连接方式
类型: 单行文本
必须: 是
默认值: 无
说明:
客户端连接Spark服务端可选择以下连接方式之一:
- Amazon EC2: scripts that let you launch a cluster on EC2 in about 5 minutes
- Standalone Deploy Mode: launch a standalone cluster quickly without a third-party cluster manager
- Mesos: deploy a private cluster using Apache Mesos
- YARN: deploy Spark on top of Hadoop NextGen (YARN)
- Kubernetes: deploy Spark on top of Kubernetes
例如,选择Standalone Deploy Mode模式模式,可设置:
spark://192.168.28.201:7077
批量写
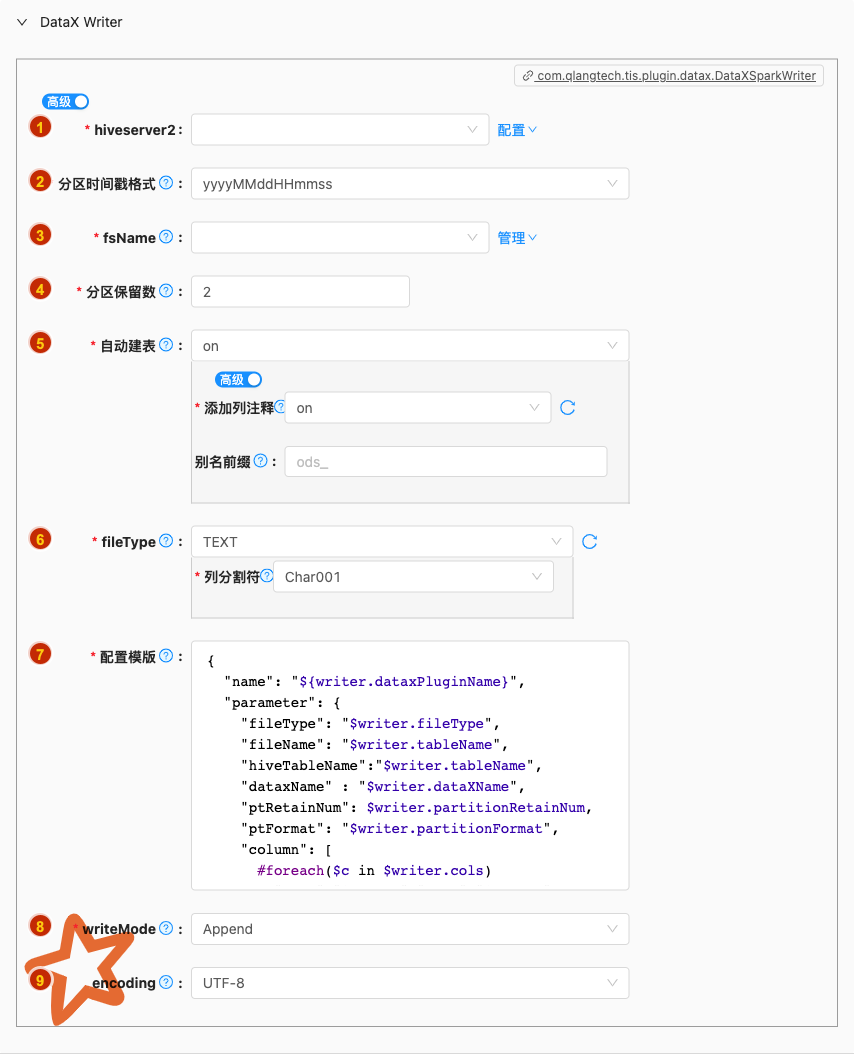
- 配置项说明:
hiveserver2
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 无
分区时间戳格式
类型: 单选
必须: 是
默认值: yyyyMMddHHmmss
说明:
每进行一次DataX导入在Hive表中会生成一个新的分区,现在系统分区名称为'pt'格式为开始导入数据的当前时间戳,格式为
yyyyMMddHHmmss或者yyyyMMdd
fsName
- 类型: 单选
- 必须: 是
- 默认值: 无
- 说明: 描述:Hadoop hdfs文件系统namenode节点地址。格式:hdfs://ip:端口;例如:hdfs://127.0.0.1:9000
分区保留数
类型: 整型数字
必须: 是
默认值: 2
说明:
每进行一次DataX导入在Hive表中会生成一个新的分区,现在系统分区名称为
pt格式为开始导入数据的时间戳
自动建表
- 类型: 单选
- 必须: 是
- 默认值: on
- 说明: 解析Reader的元数据,自动生成Writer create table DDL语句
fileType
- 类型: 单行文本
- 必须: 是
- 默认值: TEXT
- 说明: 描述:文件的类型,目前只支持用户配置为"text"
配置模版
- 类型: 富文本
- 必须: 是
- 默认值: com.qlangtech.tis.plugin.datax.DataXHiveWriter.getDftTemplate()
- 说明: 无特殊情况请不要修改模版内容,避免不必要的错误
writeMode
类型: 单选
必须: 是
默认值: append
说明:
hdfswriter写入前数据清理处理模式:
- append: 写入前不做任何处理,DataX hdfswriter直接使用filename写入,并保证文件名不冲突,
- nonConflict:如果目录下有fileName前缀的文件,直接报错
encoding
- 类型: 单选
- 必须: 否
- 默认值: utf-8
- 说明: 描述:写文件的编码配置。