TIS实现千表入湖之Apache Paimon篇
摘要:传统大数据方案(如Hive/Spark)虽能低成本处理海量数据,却难以实现高效实时写入。数据湖技术成功解决了这一矛盾,而Apache Paimon凭借其流批一体架构、深度集成Flink引擎和卓越的实时更新能力,成为实时数仓领域的新标杆。本期视频将带你深入解析Paimon的核心原理,并演示如何通过TIS平台快速实现整库实时同步至Paimon数据湖的全流程实践!
背景
传统数据仓库构建方案中,Hive 与 Spark 凭借其出色的 Map/Reduce 执行能力,能够高效处理海量原始数据并生成目标结果。同时,由于它们支持将数据持久化在本地 HDFS 或云厂商提供的分布式文件系统(如阿里云 OSS、亚马逊 S3 等),天然具备近乎无限的扩展性与低廉的存储成本。然而,这类基于分布式文件系统的方案普遍存在一个短板:难以实现高效的实时数据写入。廉价存储与高效实时写入,一度看似不可兼得。
近年来,以 Apache Paimon、Hudi 和 Iceberg 为代表的数据湖技术逐渐成为主流,它们各自以不同的架构思路成功平衡了这一对矛盾。 其中,Apache Paimon 凭借与 Flink 生态的深度整合、基于 LSM-Tree 结构带来的高效写入性能,以及更优的流批一体支持,在实时数据湖领域展现出独特优势。 相比 Hudi 和 Iceberg,Paimon 在实时更新、局部更新和 Flink 集成友好性方面表现更为出色,尤其适合构建高吞吐、低延迟的实时数仓场景。
本文将系统介绍 Apache Paimon 的核心架构与原理,阐述其与 TIS 平台的深度整合机制,并讲解如何通过 TIS 快速、一站式地完成整库实时同步至 Paimon 数据湖的实践方法。
TIS 站在 Flink-CDC 巨人的肩膀上
当前,Flink-CDC 提供了业界领先的数据写入 Apache Paimon 表的能力,支持多种数据源,涵盖批量历史快照数据同步与近实时增量写入。为进一步简化同步管道的配置流程,Flink-CDC 自 3.0.0 版本起引入了基于 YAML 的配置驱动方式。该方式通过声明式语法统一管理数据源、目标和管道行为,大幅提升了配置的可读性与复用性,降低了用户编写和维护 Flink SQL 或 DataStream API 代码的复杂度。
以下是一段使用 Flink-CDC Pipeline 实现从 MySQL 同步至 Paimon 表的 YAML 配置示例:
source:
type: mysql
name: MySQL Source
hostname: 127.0.0.1
port: 3306
username: admin
password: pass
tables: adb.\.*, bdb.user_table_[0-9]+, [app|web].order_\.*
server-id: 5401-5404
sink:
type: paimon
name: Paimon Sink
catalog.properties.metastore: filesystem
catalog.properties.warehouse: /path/warehouse
pipeline:
name: MySQL to Paimon Pipeline
parallelism: 2
该配置简洁明了,适用于演示场景。然而在实际生产环境中,用户往往需要根据业务表类型(如事实表与维表)进行差异化配置。例如,事实表通常需设置合理的分区与分桶策略以提升查询性能,具体需考虑如下方面:
- 选择适当的分区键,并预设合理数量的分区;
- 确定分桶模式,并选取合适的列作为 Bucket 的 Hash 键;
- 配置 LSM-Tree 相关参数以保障查询时效性,如内存缓存记录条数、Flush 触发条件、L0 层文件大小与 Compaction 策略等;
- 其他影响数据可见性、查询性能与写入稳定性的高级参数。
扩展后的 Sink 部分配置示例如下:
sink:
type: paimon
name: Paimon Sink
catalog.properties.metastore: filesystem
catalog.properties.warehouse: /path/warehouse
table.properties.partition: dt
table.properties.bucket: 4
table.properties.bucket-key: user_id
table.properties.sink.buffer-flush.max-entries: 1000
table.properties.sink.buffer-flush.interval: 30s
table.properties.compaction.min.file-num: 3
table.properties.compaction.max.file-num: 10
table.properties.compaction.early-max.file-num: 8
# Snapshot 相关配置
table.properties.snapshot.time-retained: 2h
table.properties.snapshot.num-retained.min: 5
table.properties.snapshot.num-retained.max: 10
可见,一份真正可用于生产环境的 Pipeline 配置远非演示配置那样简单,需综合考虑各类性能与稳定性参数,配置过程繁琐且容易出错。
另外,这套运行环境部署也有较高门槛,在编写Pipeline Yaml配置前用户还需要搭建Flink-CDC运行环境,包括诸多繁琐步骤,下载并部署Flink及Flink-CDC的Release包、下载并部署Flink-CDC相关数据同步源和目标端相关插件Jar。
需要有Java领域的开发经验,熟悉Flink框架,这对普通小白用户来说是无法胜任的。
TIS的愿景是能够让普通小白用户也能零代码乐高式搭建数据管道,为了避免重复造轮子,Flink-CDC在数据同步功能内核级别已经实现得非常优秀,TIS所有做的是将Flink-CDC的功能内核嫁接,在产品层面最大限度地屏蔽底层技术细节
,让数据同步通道部署和构建的门槛降到最低,终端用户可以傻瓜式地开箱即用。下文将着重介绍为了实现以上目标,在TIS中做了哪些改造。
TIS中是如何实现的?
领域建模
TIS 在现有 Flink-CDC 架构基础上,对 Pipeline 进行重构与整合,摒弃原生的 YAML 配置驱动方式。通过将 Paimon 数据同步流程中涉及的关键配置抽象为统一的模型 ,并且TIS 实现从前端 UI组件 至底层执行逻辑的模型自动化映射。通过这套流程显著降低了用户的操作复杂度,大幅提升生产环境中将各类数据源同步至 Paimon 表构建流程的效率。
以下是对Paimon Sink端相关抽象实体建模的UML类图:
在以上类图中有以下重要的实体:
- PaimonCatalog:TIS提供了支持Hive MetaClient的Catalog
- PaimonSnapshot:对Snapshot相关的概念参数封装
- PaimonWriteBuffer:对LSM Tree中MemoryBuffer存储区建模,例如,设置缓冲区写入记录数阈值大小
writeBufferSize - PaimonBucket:对Bucket概念进行建模,支持Paimon官网支持的三种类型:
- Fixed Bucket:FixPaimonBucket
- Dynamic Bucket:实现类DynamicPaimonBucket
- Postpone Bucket:实现类PostponePaimonBucket
- PaimonCompaction: 对Compaction概念进行建模,将影响Paimon Compaction行为的参数封装,Paimon 的Compaction Compaction行为对Paimon 客户端查询的性能有很大关系,需要认真设置。
- PaimonPartition:对Paimon表分区概念建模,如为事实表(按照时间推进会创建大量新的记录,同时为了保证查询高效可以按照记录中某些字段进行分区物理隔离,需要打开数据分区功能,设置用以hash散列函数的列名)
- PaimonSequenceFields:为了保证同步数据不被脏写,可以设置序列字段属性。
- PaimonBucketKeys:在某个物理分区中,会继续将数据分割成多个数据分桶(Bucket),如需使用非默认分桶规则(默认取Paimon表主键取hash值取模获得分桶序列),用户也可以使用自定义字段列作为以hash散列函数的列。
对领域模型设计定稿之后,利用TIS强大的领域模型映射器能自动将领域模型映射生成前端UI组件,生成的Paimon前端UI组件效果,详细请查看:领域模型对应前端UI组件
打通Flink-CDC的任督二脉
Flink-CDC 自 3.0.0 版本起引入了基于 YAML 的配置驱动Pipeline管道同步方式。 这是一次重大的改造升级,他不仅仅是我们看到的配置方式的变化,还包括底层架构的整体改造,将原先消息管道中传输的RowData切换成了以Event为主的传输体系,由此带来了一些列新的使用方式。 自此版本后Flink-CDC存在两套数据同步管道执行模式,如下图:
Flink CDC 采用Pipeline架构之后有新特性:
- 数据管道变成消息总线:之前采用Stream API的方式如果需要实现数据库全表同步,每个独立的表会单独建立一个管道,试想整库同步的表数量比较多,会创建大量管道,这样会浪费计算资源。采用Pipeline的同步方式后,不同表的增量同步消息复用同一个管道。
- 支持Schema Evolution:表实体的DDL更新消息,都派生于同一个抽象实体Event,使得Flink-CDC可以在Pipeline架构下实现Schema Evolution。
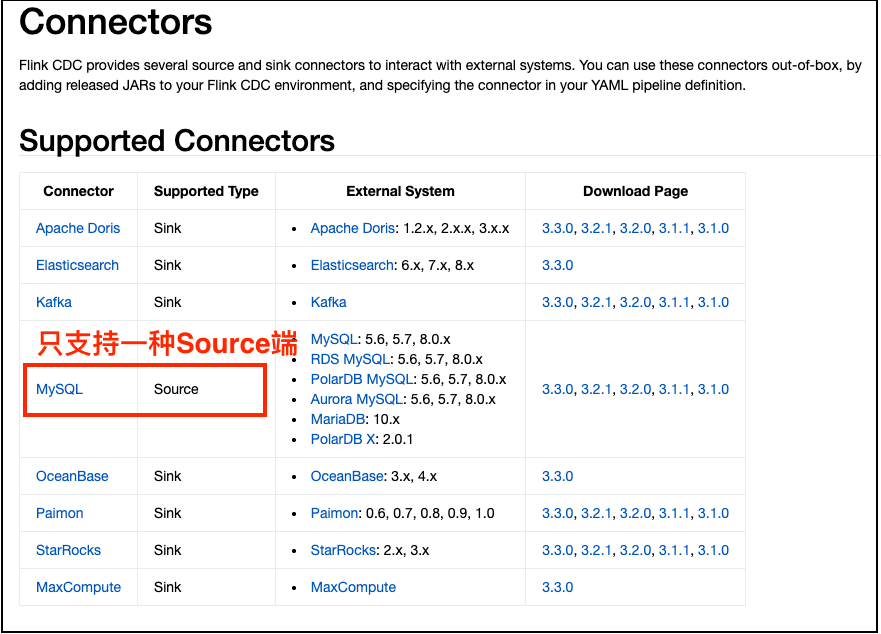
可是,细心的读者查看Flink-CDC官方Pipeline Connectors的Supported Connectors 发现Supported Type为Source的端只有MySQL这一个,说白了,Flink-CDC官方Pipeline的功能有点单薄,Source端只有MySQL一种,其他类型如:SqlServer,PostgreSQL,Oracle,MongoDB,Kafka都不支持。
复用优先,自研为后。恪守“不要重复造轮子”之训,亦不忘“操家伙自己撸”之魂,TIS团队很快想到了一个办法,将原基于Stream RowData Connectors通过Flink的算子桥接适配嫁接到 Pipeline管道中,以最低的代价且可靠的方式让Pipeline管道 扩展多种源端数据端类型,原理如下图:
桥接适配相关的核心类:
经过适配,Flink CDC Pipeline的Source端不再只限于MySQL,其他主流数据端类型也纳入其中,打通了Flink-CDC的任督二脉。下游Sink端Paimon数据湖真的能够实现海纳百川了。
实操演练
说再多都不如自己亲自上手进行一番操作,才会有最真切的感受。操作分为几个步骤:
- 基础环境部署
- 在TIS控制台中构建数据管道并运行
- 验证数据同步效果
基础环境部署
部署Apache Paimon
为了演示效果,能够快速在本地部署,使用docker-compose方式部署支持Paimon表的Hive运行环境,部署步骤如下:
下载
okhive.tar,包内有用于hive docker-compose运行所依赖的所有资源文件,执行:wget http://mirror.qlangtech.com/okhive.tar解压
okhive.tar并且启动支持Paimon表的Hive环境,执行如下脚本:tar xvf okhive.tar
cd okhive
docker-compose -f docker-compose-paimon.yml up -dtip本地如还没有部署Docker-Compose运行环境,请查阅文档: https://docs.docker.com/compose/
确认docker container启动成功:
docker-compose -f docker-compose-paimon.yml ps显示如下:NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
okhive-datanode-1 bde2020/hadoop-datanode:2.0.0-hadoop2.7.4-java8 "/entrypoint.sh /run…" datanode 3 months ago Up 19 seconds (health: starting) 0.0.0.0:50010->50010/tcp, :::50010->50010/tcp, 0.0.0.0:50075->50075/tcp, :::50075->50075/tcp
okhive-hive-metastore-1 bde2020/hive:2.3.2-postgresql-metastore "entrypoint.sh /opt/…" hive-metastore 3 months ago Up 19 seconds 10000/tcp, 0.0.0.0:9083->9083/tcp, :::9083->9083/tcp, 10002/tcp
okhive-hive-metastore-postgresql-1 bde2020/hive-metastore-postgresql:2.3.0 "/docker-entrypoint.…" hive-metastore-postgresql 3 months ago Up 20 seconds 5432/tcp
okhive-hive-server-1 bde2020/hive:2.3.2-postgresql-metastore "entrypoint.sh /bin/…" hive-server 3 months ago Up 19 seconds 0.0.0.0:10000->10000/tcp, :::10000->10000/tcp, 10002/tcp
okhive-namenode-1 bde2020/hadoop-namenode:2.0.0-hadoop2.7.4-java8 "/entrypoint.sh /run…" namenode 3 months ago Up 19 seconds (health: starting) 0.0.0.0:8020->8020/tcp, :::8020->8020/tcp, 0.0.0.0:50070->50070/tcp, :::50070->50070/tcp
okhive-presto-coordinator-1 shawnzhu/prestodb:0.181 "./bin/launcher run" presto-coordinator 3 months ago Up 19 seconds 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp
下载TIS单机版Release包并部署,使用TIS单机版部署,详细请查看: TIS单机版安装说明
下载 TIS定制版Flink1.20.1 Release包并部署,使用Flink Standalone方式部署,详细请查看:Flink Standalone安装说明
本地环境中部署一个可用的MySQL数据库,内有现成的数据表并且表内有记录可查询供测试用
原理说明&实操演练
总结
本文系统介绍了 TIS 平台与 Apache Paimon 的深度整合方案,旨在解决传统数据仓库在实时写入方面的短板。
通过站在 Flink-CDC 的肩膀上,TIS 摒弃了复杂的 YAML 配置方式,转而采用领域建模将 Paimon 的核心概念(如 Catalog、Snapshot、WriteBuffer、Bucket 等)抽象为统一的模型,并自动映射生成前端 UI 组件,极大降低了用户的操作门槛。
此外,TIS 创新性地通过桥接适配机制,扩展了 Flink-CDC Pipeline 的源端支持,使其不再局限于 MySQL,从而实现了多源数据的高效同步。
最终,TIS 提供了一套从环境部署、管道配置到数据验证的完整实践方案,让用户能够以“乐高式”的简单操作,构建稳定、高效的实时数据湖同步管道,真正实现了廉价存储与高效实时写入的兼得。